Künstliche Intelligenz (KI) (englisch: Artificial Intelligence / AI) kann definiert werden als Intelligenz, die ausschließlich von Maschinen wie beispielsweise Robotern und Cyber-physischen Systemen ausgeht. Das Forschungsgebiet KI versucht dabei die menschlichen Wahrnehmung sowie das menschlichen Handeln zu verstehen und nachzubilden. Geht es nach der Forschung, handelt es sich also um Systeme, die sich dem menschlichen Denken annähern, es nachahmen, replizieren, automatisieren oder es gar übertreffen und verbessern.
Das Forschungsgebiet KI konzentriert sich dabei nicht auf eine einzelne, einheitliche Technologie. Vielmehr handelt es sich um zusammenhängende technologische Elemente (Software und Hardware), deren Einsatz sehr vielfältig ist und von der jeweiligen Problemstellung abhängt. Allgemein lässt sich sagen, dass Künstliche Intelligenz aus wahrnehmenden, verarbeitenden und lernenden Elementen besteht; sie lässt sich in die beiden Teilbereiche maschinelles Lernen (englisch: Machine Learning) und tiefgehendes Lernen (englisch: Deep Learning) gliedern.
Anwendung / Einsatzgebiete KI allgemein
Für den praktischen Einsatz in Unternehmen gibt es zahlreiche Beispiele[1]
- Prüfung und Beurteilung (Musterklassifikation): Kreditwürdigkeitsprüfung, Insolvenzprüfung, Bilderkennung
- Klassenbildung (Clustering): Marktsegmentierung, Data Mining
- Prognose (Prediction): Kursprognosen, Absatzprognosen, Kostenprognosen
- Optimierung: Transportoptimierung (Travelling-Salesman-Problem), Reihenfolgeplanung
KI und der Teilbereich Machine Learning
Machine Learning (ML) hat im eigentlichen Sinn nichts mit Künstlicher Intelligenz zu tun. Vielmehr setzt ML auf eine Mustererkennung, die von Maschinen beziehungsweise Computern erledigt werden kann. Statt Maschinen klar definierte Regeln vorzugeben, um sie zu verbessern (das heißt, sie besser zu machen beim Lösen einer Aufgabe), sollen sie (‚selbstständig‘) aus Daten lernen. ML ist so die einfachste und auch günstigste Variante, Computern eine Art ‚künstliche‘ Intelligenz zu vermitteln. Auch in der Intralogistik bezieht sich ML nicht ausschließlich auf Maschinen, vielmehr beschreibt es eine Funktionsweise, die ebenso bei Prozessen und Algorithmen angewandt wird.
Auf Basis von großen Datenmengen, sogenannten Trainingsdaten, und Algorithmen werden Trainingsphasen koordiniert, die dazu führen, dass die eingesetzte Software die Fähigkeit erlangt, sich selbst zu modifizieren beziehungsweise dazuzulernen. Klassische Beispiele für Machine Learning sind etwa die lernenden Algorithmen ‚Naive Bayes’ und ‚Collaborative Filtering‘. Letzteren kennt man beispielsweise von der Onlineplattform Amazon: ‚Kunden, die diesen Artikel gekauft haben, kauften auch‘. Das ‚Naive Bayes‘-Verfahren wird dagegen innerhalb von Spam-Filtern beim E-Mail-Management eingesetzt. Die eigentliche Intelligenz bei Machine-Learning-Systemen ist die Fähigkeit, sich selbst zu modifizieren – sobald mehr Informationen beziehungsweise Daten zur Verfügung stehen. Stehen einem ML-System qualitativ hochwertige Daten (siehe auch Smart Data) zur Verfügung, kann sogar auf menschliche Intervention verzichtet werden.
KI und der Teilbereich Deep Learning / Neuronale Netze
Deep Learning beruht technologisch auf künstlich erzeugten neuronalen Netzen, kurz KNN (englisch: Artificial Neural Network / ANN). Die Algorithmen des tiefgreifenden Lernens orientieren sich in den meisten Anwendungsfällen an der Funktionsweise des menschlichen Gehirns. Die KNN-Rechenmodelle, beziehungsweise die zum Einsatz kommenden Algorithmen, lernen wie ihr menschliches Vorbild aus der Erfahrung, indem sie individuell die simulierten Neuronenverbindungen anpassen.
Aufbau eines neuronalen Netzes
Die Neuronen eines künstlichen neuronalen Netzes sind dabei schichtweise in sogenannten Layern angeordnet und in der Regel in einer festen Hierarchie miteinander verbunden. Die Neuronen sind zumeist zwischen zwei Layern verbunden (Inter-Neuronlayer-Connection), in selteneren Fällen aber auch innerhalb eines Layers (Intra-Neuronlayer-Connection).
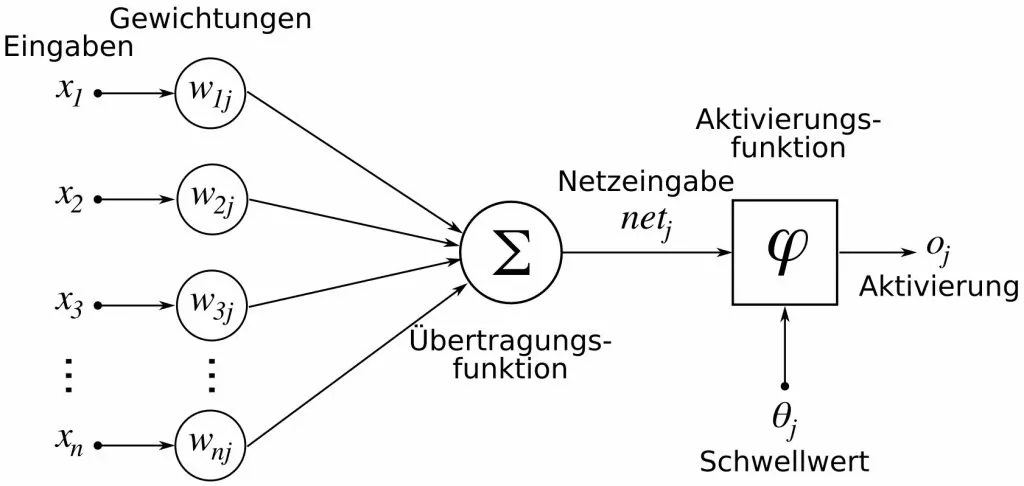
Hinweis der Redaktion: Die Effektivität eines neuronalen Netzes liegt also in seiner Vernetzung. So sind die oben erwähnten Layer oder die einzelnen Schichten mittels einzelner Neuronen miteinander verknüpft – sprich, jedes Neuron einer Schicht immer mit allen Neuronen der nächsten Schicht. Einzelne Informationen fließen also in die sogenannte Eingabeschicht, die wiederum die Informationen an Zwischenschichten (Hidden Layers) abgibt; am Ende werden die interpretierten Daten über die Ausgabeschicht abgegeben – dabei ist der Output des einen Neurons der Input des nächsten. Bezieht ein neuronales Netzwerk neue Daten, dann werden diese Verbindungen verstärkt oder verringert; ebenso kann jede Verbindung in einem neuronalen Netzwerk angepasst werden, indem einem Merkmal eine größere oder kleinere Relevanz zugeschrieben wird.
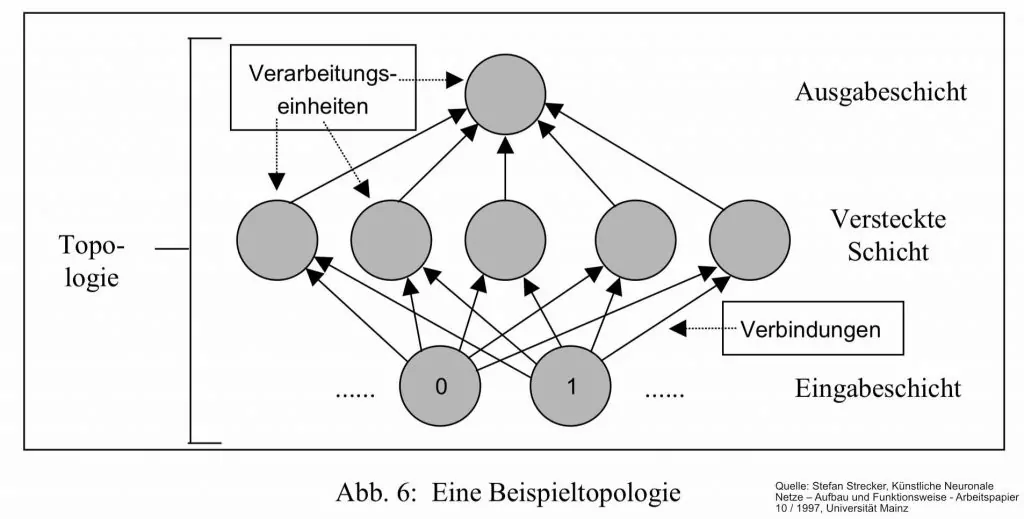
Künstliche Neuronale Netze weisen grundsätzlich sogenannte Kernkomponenten beziehungsweise Grundbausteine auf, die sich in allen Netzwerktypen wiederfinden[2].
- Verarbeitungseinheiten (processing elements)
- Verbindungen zwischen Verarbeitungseinheiten
- die Netzwerktopologie
Die unten aufgelisteten dynamischen Kernkomponenten beschreiben die Informationsverarbeitung, die innerhalb der KNN stattfindet. Die Verarbeitungsintervalle sind in folgende Phasen aufgeteilt.
- Lernphase
- Verarbeitungsphase
KI: Elemente der Wahrnehmung
Künstliche Intelligenz muss Informationen aufnehmen können, um in der Lage zu sein, die reale Welt zu verstehen beziehungsweise wahrzunehmen. Somit muss KI die Fähigkeit haben, Texte zu verarbeiten, Bilder und Videos zu erfassen, Töne aufzunehmen und ebenso Informationen über Umweltbedingungen, wie beispielsweise Temperatur, Wind und Nässe, zu erfassen. In diesem Zusammenhang spielt das Internet der Dinge (Internet of Things / IoT) eine große Rolle, da es hierbei darum geht, heterogene Daten von unzähligen heterogenen Geräten zu sammeln, daraus Schlüsse zu ziehen und zu lernen; eine Aufgabe, die heutzutage auch fortgeschrittene Datenanalysewerkzeuge vor große Herausforderungen stellt. Verkürzt lässt sich sagen, dass das IoT aus der Gesamtheit der gesammelten Informationen besteht: Welche Geräte befinden sich in Verwendung? Wie sind diese Dinge verbunden? Wie werden die Daten gesammelt? Was kann man aus diesen Daten lernen? Und – letztendlich – was kann man in deren Konsequenz anders machen?
Um die Aufnahme der Informationen zu gewährleisten, benötigen KI-Systeme grundsätzlich Sensoren, die für sie die Außenwelt erfassen (sehen / hören / ‚riechen‘) um nachfolgend bestimmte Handlungen und Aktivitäten auszuüben. Die Sensoren sind beispielsweise in Kameras, Mikrofonen und innerhalb von Robotik-Systemen verbaut.
KI: Elemente der Datenverarbeitung und des Lernens
Die Basis zur selbstständigen Generierung von Wissen und für den Aufbau eines Erfahrungsschatzes bilden bei KI-Systemen Trainingsdaten; diese sind die Voraussetzung aller maschinellen Lernverfahren. Erst mittels eines ausreichend großen Datensatzes kann das System Gesetzmäßigkeiten und Muster erkennen, wodurch es wiederum auch neue, noch unbekannte Probleme lösen kann. Hierbei lassen sich drei Trainingsarten unterscheiden:
- Überwachtes Lernen (Supervised Learning)
- Unüberwachtes Lernen (Unsupervised Learning)
- Bestärkendes Lernen (Reinforcement Learning)
Beim überwachten Lernen werden zu Beginn – meist manuell und verbunden mit einem großen Aufwand – alle Trainingsdaten mit einem Label versehen, wodurch schon im Voraus zu jedem Datenpunkt die zugehörige Lösung bekannt ist. Das System lernt nun in der Trainingsphase, unbekannte Daten richtig zuzuordnen. Dabei kann die Qualität des ML-Systems exakt bewertet werden, denn die Lösung wird als eindeutig richtig beziehungsweise eindeutig falsch klassifiziert. So gehören zu den typischen Einsatzgebieten des überwachten Lernens das Lösen von Klassifikations- und Regressionsproblemen.
Im unüberwachten Lernen dagegen ist anfangs keine Lösung im eigentlichen Sinn bekannt. Es geht vor allem darum, vorhandene Daten so zu verstehen, dass Strukturen, Muster und eventuelle Gruppierungen aufgedeckt werden. Da es hierbei keine eindeutige Lösung gibt (es werden auch keine Regeln vorgegeben), ist eine Bewertung, wie erfolgreich das System letztendlich funktioniert hat, nicht wirklich möglich. Dafür ist es aber in der Lage, Zusammenhänge zu erkennen, die bis dato nicht offensichtlich waren. Demnach eignet sich das unüberwachte Lernen insbesondere für Clusteranalyse und -bildung; ebenso für die Dimensionsreduktion bei großen Datenmengen, um Komplexität beherrschbarer zu machen beziehungsweise Vorarbeit für andere Algorithmen zu leisten.
Beide Trainingsmethoden können auch zusammen angewandt werden, sowohl sequenziell als auch kombiniert.
Das bestärkende (auch: verstärkende) Lernen zeichnet sich dadurch aus, dass es auf eine Trial-and-Error-Strategie setzt und sich somit deutlich von den anderen beiden Trainingsmethoden unterscheidet. In der Regel trifft das System eine Reihe von Entscheidungen, deren Ergebnis aber erst hinterher bewertet wird. Dafür kann es sowohl belohnt als auch bestraft werden; das permanente Ziel besteht darin, die Belohnungen zu maximieren und die Bestrafungen zu minimieren. Daraus entwickelt sich nach einiger Zeit eine optimale Strategie, da das System gelernt hat, welche Entscheidungen in welcher Situation honoriert werden. Das Reinforcement Learning kommt typischerweise bei der Entwicklung von Spielstrategien zum Einsatz.
Beispiele für den Einsatz von KI
Service-Chatbots
Künstliche Intelligenz soll in Zukunft den Menschen dort ersetzen, wo rechnergestützter Service schneller und qualitativ hochwertiger kundenseitig zum gewünschten Ergebnis führt. Service-Chatbots etwa erleichtern Kunden die Suche nach Informationen und führen einfache Transaktionen über Sprach- oder Chat-Schnittstellen aus. Machine-Learning-Algorithmen scannen eine Vielzahl von Produkten und technischer Dokumentationen und antworten automatisch auf häufige Fragen. Dabei ist zu erwähnen, dass solche Systeme sich ausschließlich auf einfache und grundlegende Fragen konzentrieren.
In Zukunft werden Nutzer immer weniger auf Webseiten nach relevanten Informationen suchen, sondern dem Chatbot einfach eine Frage stellen.
Rudolf Grötz, Senior Technical Engineer bei Raiffeisen Bank International – ix Magazin für professionelle Informationstechnik / 06/2018, Seite 50 [3]
KI und Logistik/Intralogistik
Die Anwendung künstlicher Intelligenz bietet sich insbesondere im Bereich der Logistik beziehungsweise der Intralogistik an – und zwar in nahezu allen Bereichen der Supply Chain. Im Logistikbereich eines Unternehmens sowie innerhalb der Logistikkette aller beteiligten Unternehmen fallen täglich Unmengen an Daten an, die sowohl strukturiert als auch unstrukturiert vorliegen; für das Ausschöpfen dieser Informationen ist Künstliche Intelligenz prädestiniert. So kann KI dabei unterstützen, Methoden und Verhaltensweisen neu zu entwickeln, beispielsweise aus reaktiven Vorgängen proaktive zu generieren, und im Sinne der Planungssicherheit statt Mutmaßungen und groben Schätzungen konkrete Voraussagen zu treffen. Natürlich ist es auch möglich, sich lediglich auf die bestehenden Prozesse zu konzentrieren; manuelle wie auch bereits automatisierte Abläufe lediglich zeitlich zu optimieren. Zudem können Dienstleistungen, statt generischen Standards zu folgen, personalisiert und somit kundenfreundlicher gestaltet werden.
Ein Beispiel zeigt, wie eklatant die Vorteile künstlicher Intelligenz in der Intralogistik sein können: In einem Markt sind wegen manueller Bestellung 7,5 Prozent der Artikel wegen Regallücken nicht verfügbar. Die Fehlerquote sinkt auf fünf Prozent, wenn eine spezielle KI-Software einem menschlichen Disponenten Empfehlungen ausspricht. Wird auf die Möglichkeit menschlicher Korrekturen verzichtet und künstliche Intelligenz führt die Lager- und Logistikaufgaben vollkommen autonom durch, so sinkt die Fehlerquote auf 0,5 Prozent.
Joachim Bengelsdorf / diyonline-Magazin[4]
Logistische Beispiele: Künstliche Intelligenz
Als erster Einsatzort für eine breitflächig eingesetzte Künstliche Intelligenz gilt die Lagerlogistik. Man spricht auch vom Learning Warehouse. Dort wird bereits heutzutage eine große Menge an Informationen von Algorithmen analysiert.
- Dem geht voraus, dass die KI mit annähernder Exaktheit bereits in der Lage ist, das Stattfinden bestimmter Ereignisse (via E-Commerce, Multi-Channel, Cross-Channel) vorauszusagen. Indem zum Beispiel Bestellverhalten tiefer analysiert wird, können zuverlässige Aussagen (und somit Maßnahmen) bezüglich zukünftiger Bestellungen / Aufträge getroffen werden, auch um einen schnelleren Versandprozess zu ermöglichen. Wichtig dabei: Innerhalb eines Lagers sind die Prozesse so automatisiert, sodass die jeweiligen Abläufe, egal ob beispielsweise Wareneingang, Einlagerung, Auslagerung / Umlagerung, Kommissionierung, Veredelung und Warenausgang, zeitlich klar definiert sind; eine zuverlässige Aussage auf Basis der Interlogistik ist demnach immer möglich.
- Ebenfalls gängige Praxis ist das Erkennen von Trendartikeln zu einem bestimmten Zeitpunkt. Die verantwortlichen Mitarbeiter können dann bei Bedarf die Produktbelegung im Lager anpassen, um etwa eine Wegeoptimierung während der Kommissionierung zu forcieren; ähnlich dem Prinzip Schnell- und Langsamdreher.
- Auch anstehende Wartungen oder Verbesserungspotenziale im Materialfluss lassen sich auf diese Weise identifizieren. Dies stellt einen bedeutenden Schritt in Richtung kognitiver Logistik dar, die im Hinblick auf die potentielle Reduzierung der Fehlerquote das große Ziel innerhalb der Supply Chain ist. Denn mithilfe der dafür nötigen Semantik können Objekte nicht nur maschinenverstehbar in Beziehung gebracht werden, Mitarbeiter und das führende Management können auch in Echtzeit von einem Pick (beispielsweise Pick-by-MDE) zum Auftrag oder zum ursprünglichen Avis im Wareneingang navigieren, um so relevante Rückschlüsse zu erhalten. Speziell die semantische Analyse von logistischen Prozessen ist ein besonderes Verfahren der Informationsgewinnung, welches grundsätzlich die inhaltliche Interpretation von Kennzahlen erlaubt und dank der Einbeziehung von Domänenwissen (Synonyme, Ähnlichkeiten, Ontologien sowie Taxonomien) exakte Ergebnisse liefert. Für die Zukunft ist es denkbar, dass intelligente Systeme so Entscheidungen auf der Grundlage von ‚Predictive Analytics‘, vollkommen ohne menschliches Eingreifen, treffen.
- Ebenfalls erwähnenswert: Auch die Optimierung der Zusammenarbeit von Menschen und Robotern (Mensch-Maschine-Schnittstelle) ist ein praktikables Einsatzgebiet Künstlicher Intelligenz; und zwar indem Roboter von Menschen lernen. Mittels virtueller Realität und 3D-Modulation kann der Mensch automatisch digitale Informationen generieren. Als Beispiel kann hier etwa eine spezielle Handbewegung zum Greifen einer einzelnen Position dienen. Die Bewegung kann millimetergenau gemessen werden und vermag es auf diese Weise, das Greifen von Robotern innerhalb der Kommissionierung (Pick-by-Robot) zu verbessern.
Artificial intelligence makes the warehouse of the future more dynamic, more agile, and more responsive. The intelligent networking of machine, process and product information is a quantum leap for process optimization.
Tim Eick, Head SynQ Competence Center, Swisslog Logistics Automation
Zusammenfassung Künstliche Intelligenz
Von der Rundgangsoptimierung, Bestandsverwaltung bis hin zur Batchbildung und den dadurch entstehenden Synergieeffekten bei der Auftragseinlastung; Künstliche Intelligenz und ihre Algorithmen unterstützen schon jetzt den Lagermitarbeiter durch gezielte Prozessoptimierung (siehe auch Leitstand in der Intralogistik). In Zukunft werden sogenannte kognitive Systeme über die Fähigkeit verfügen, zu lernen, Muster zu erkennen und daraus Handlungsempfehlungen abzuleiten – und dies, ohne in Abhängigkeit zur menschlichen kognitiven Fähigkeit zu stehen. So können sie die Mitarbeiter im Lager bei Entscheidungen unterstützen oder sie bereits im Vorfeld auf wahrscheinlich eintretende Ereignisse hinweisen.
Weiterführende Links:
- Kognitive, vernetzte Produktionssysteme
- Cyber-physische Systeme in der Logistik
- Zurück zur Startseite
Quellen:
[3] ix Magazin für professionelle Informationstechnik / 06/2018, Seite 50
[4] diyonline.de / AI als Chance für die Intralogistik
Sie interessieren sich für die Automatisierung, dann lesen Sie auch die Artikel Computer-integrated Manufacturing sowie Smart Factory / die intelligente Fabrik.
Also available in English (Englisch)


